Perl提供了一个Storable模块,用来对数据结构进行序列化(serialization,Perl中称为冻结),也就是将数据结构保存为二进制数据。
- 序列化后的数据可以写入文件实现持久化,可以将持久化文件拷贝给远程机器
- 也可以通过网络套接字将序列化数据传递给远程机器
- 序列化后的数据在任意机器上都可以反序列化(deserialization,Perl中称为解冻)得到原始的数据结构
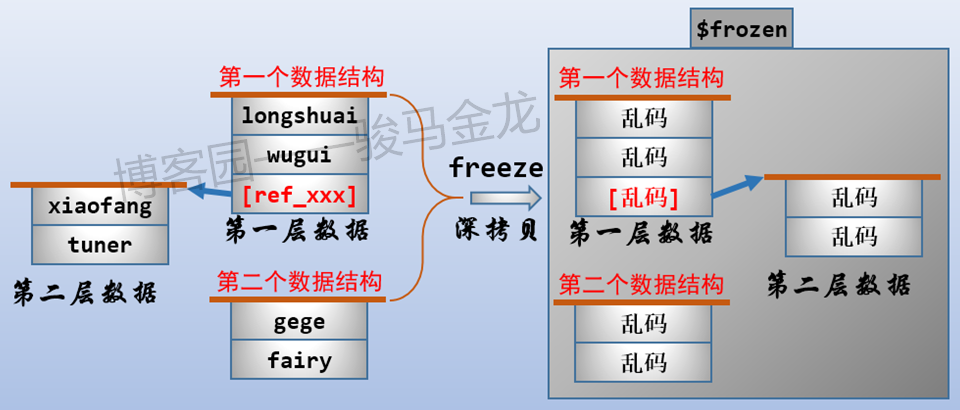
- 序列化数据结构时是进行深拷贝的,序列化完成后,修改原始数据,不会影响反序列化的结果
序列化:freeze、nfreeze和thaw
Storabel的freeze和thaw函数分别用来冻结(序列化)和解冻(反序列化):
- freeze冻结的是数据对象,不包括它们的引用和名称
- freeze的参数需要是引用,可以是多个引用参数,返回的是二进制的冻结序列,各数据结构序列化在不同行
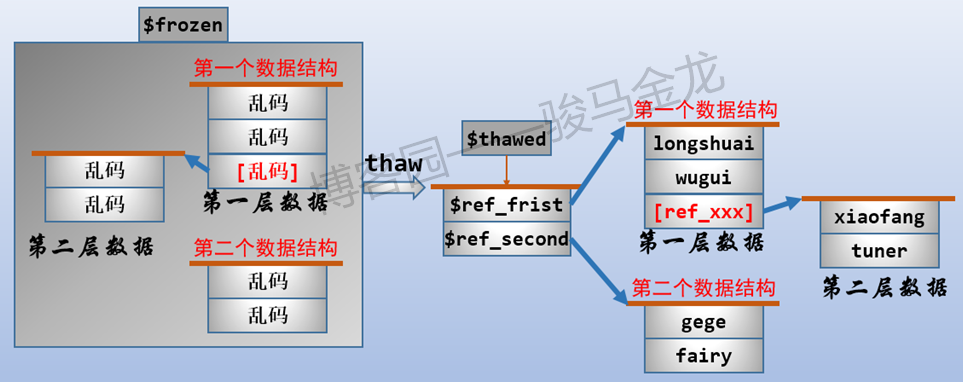
- thaw的参数是引用变量,返回的是一个匿名列表,列表各元素对应freeze冻结时的各数据结构
- nfreeze也是冻结,但是按照网络字节序进行序列化,适合远程传输序列化时的标量名称,见下一小节对主机字节序和网络字节序的描述
#!/usr/bin/perluse 5.010;use Storable qw(freeze thaw);%hash=( 'longshuai'=>{ 'gender'=>'male', 'age' =>18, 'prov' =>'jiangxi', }, 'wugui'=>{ 'gender'=>'male', 'age' =>20, 'prov' =>'zhejiang', }, 'xiaofang'=>{ 'gender'=>'female', 'age' =>19, 'prov' =>'fujian', }, );@name=('fairy',[qw(longshuai wugui xiaofang)]);$frozen = freeze [\%hash,\@name]; # 冻结引用,返回一个冻结后的列表#say $frozen; # 输出一堆乱码$thaw_out=thaw($frozen); # 解冻,返回引用列表say $thaw_out->[0]; # 输出:HASH(0x557171a4cff8)say $thaw_out->[0]{wugui}{prov}; # 输出:zhejiangsay $thaw_out->[1]; # 输出:ARRAY(0x557171a4d220)say $thaw_out->[1][1][2]; # 输出:xiaofang 上面的示例中,使用freeze冻结两个数据结构后,冻结后的二进制数据内容将赋值给一个标量变量,注意它返回的是类似于字符串那种形式的,只不过这段字符串是二进制格式的。
使用thaw解冻后,将返回一个匿名列表,列表中的元素是各冻结的数据结构的引用。对于上面的示例来说,返回值类似如此结构[$ref_hash,$ref_name],将其赋值给一个引用变量$thaw_out,然后就可以通过$thaw_out->[0]和$thaw_out->[1]分别访问这两个引用。
如下图描述:
freeze序列化过程:
thaw反序列化过程:
持久化:store、nstore和retrieve
Storable模块可以将数据结构序列化后持久化保存到文件中,或通过TCP套接字传输出去。
store和nstore用于将序列化数据进行持久化,它们用法一样,如下:
store \%ref_hash, 'file';store [\%ref_hash,\@ref_arr], 'file';nstore \%ref_hash, 'file';nstore [\%ref_hash,\@ref_arr], 'file';
但是store存储序列化数据时默认采用的是主机字节序(host byte order),nstore默认采用的是网络字节序(network byte order),采用网络字节序可以保证被TCP套接字传输出去时,远程主机能以完全一致的字节序方式读取数据。所以,要想通过网络传输序列化的对象时,需要使用nstore。
小知识:主机字节序和网络字节序
多字节数据对象在存储时,必须考虑两个问题:
- 这段数据对象要存储到哪个地址
- 存储时如何排列这些字节
这里不考虑存储的地址问题。对于待存储的数值"0x1122"来说,11属于高位字节,22属于低位字节。对于存储时考虑以何种字节排列方式来说,有两种方式:大端字节序和小端字节序。假设要存储的数据对象"0x1234567":
- 大端字节序(big-endian):存储时,高位在前,低位在后,所以存储的时候,和上面源数据格式一样"01 23 45 67"
- 小端字节序(little-endian):存储时,高位在后,低位在前,所以存储的时候,和上面源数据格式相反"67 45 23 01"
大端字节序对人类来说比较容易理解,但几乎所有计算机都是采用小端字节序存储的,所以也称为主机字节序。而TCP/IP协议规定,网络传输时的网络字节序都采用大端字节序传输,这样一来所有网络传输的数据都规范化,远程主机总会按照大端字节序去读取传输过来的数据。
store和nstore持久化的序列化数据可以通过retrieve函数读取并反序列化。retrieve返回的值和thaw的返回结果是一样的。
my $ref_list = retrieve 'file';
以下是nstore和retrieve的一个示例:
#!/usr/bin/perluse 5.010;use Storable qw(nstore retrieve);%hash=( 'longshuai'=>{ 'gender'=>'male', 'age' =>18, 'prov' =>'jiangxi', }, 'wugui'=>{ 'gender'=>'male', 'age' =>20, 'prov' =>'zhejiang', }, 'xiaofang'=>{ 'gender'=>'female', 'age' =>19, 'prov' =>'fujian', }, );@name=('fairy',[qw(longshuai wugui xiaofang)]);nstore [\%hash,\@name],'/tmp/tmp_data'; # 将数据序列化并持久化到文件$ref_list=retrieve '/tmp/tmp_data'; # 反序列化并读取数据say $ref_list->[0]; # 输出:HASH(0x55aee8340318)say $ref_list->[0]{wugui}{prov}; # 输出:zhejiangsay $ref_list->[1]; # 输出:ARRAY(0x55aee8340480)say $ref_list->[1][1][2]; # 输出:xiaofang 序列化到文件描述符:store_fd、nstore_fd和fd_retrieve
- store_fd、nstore_fd用于将数据结构冻结到指定的文件描述符,比如文件、管道、套接字、字符串中
- retrieve_fd则从给定的文件描述符中读取
下面示例涉及到文件句柄的标量引用,如不理解,请跳过。
例如,将数据结构冻结到一个字符串$string中存储起来:
use Storable;open my $string_fh,">",\my $string or die "...$!";nstore_fd \@data,$string_fh;close $string_fh;
从持久化数据的变量$string中解冻:
open my $string_fh1,"<",\$string or die "$!";$new_hash = fd_retrieve($string_fh1);close $string_fh1;
如此,数据结构就存储到$new_hash这个引用中。
例如,将前文的数据结构%hash存储起来,并立即解冻:
#!/usr/bin/perluse Storable qw(store_fd nstore_fd fd_retrieve);use Data::Dumper;open my $string_fh,">",\my $string;nstore_fd [\%hash],$string_fh;close $string_fh;print Dumper($string); # 输出:一大堆乱码二进制open my $string_fh1,"<",\$string or die "$!";$new_hash = fd_retrieve($string_fh1);close $string_fh1;print Dumper($new_hash); # 输出:hash数据结构
深拷贝:dclone
关于浅拷贝、深拷贝,见